

Artificial intelligence is likely to be either the best or worst thing to happen to humanity – Stephen Hawking.
De laatste jaren van zijn leven waarschuwde de beroemde wetenschapper ons voor de gevaren van kunstmatige intelligentie, en hij was niet de enige. Ook Elon Musk, Bill Gates, en Steve Wozniak uitten hun zorgen over de toekomst van deze technologie. Daarnaast wordt steeds vaker aandacht gegeven aan verkeerd gebruik van (big) data. Maar waar komt al die onrust en angst toch vandaan en is deze wel zo realistisch? In deze blog worden verschillende praktijkvoorbeelden gebruikt om de gevaren van deze technologieën te verduidelijken.
Science fiction in ons dagelijks leven
Ook al klinkt het voor sommigen onder ons als science fiction, kunstmatige intelligentie en big data worden steeds meer gewoonte binnen ons dagelijks leven. Bedrijven en overheidsinstellingen kunnen op een efficiëntere manier inspelen op de behoeften van hun klanten en burgers, processen optimaliseren, en gedrag voorspellen. Denk bijvoorbeeld aan Siri en Google Assistant die al jouw vragen zonder moeite beantwoorden; Spotify en Netflix die muziek en films aanbevelen gebaseerd op jouw eerdere interesses; en videogames waarin de complexiteit van het spel is toegenomen. Binnenkort kijken we waarschijnlijk niet eens meer gek op wanneer iemand een krantje leest achter het stuur van zijn of haar zelfrijdende auto. Maar wat hebben big data en kunstmatige intelligentie eigenlijk met elkaar te maken?
Waarom big data en kunstmatige intelligentie elkaar nodig hebben
Hoewel kunstmatige intelligentie en big data twee verschillende concepten duiden, gaan ze feitelijk hand in hand. In het kort komen de twee termen op het volgende neer. Big data beschrijft een grote hoeveelheid aan data, welke met een hoge snelheid wordt gegenereerd, complex, groot, en divers is. Het volume is zelfs te groot om met behulp van traditionele technieken te worden verwerkt. Kunstmatige intelligentie houdt zich daarentegen bezig met de ontwikkeling van een kunstmatig verschijnsel dat een vorm van intelligentie vertoont. Door algoritmes te volgen en patronen te herkennen, nemen dit soort apparaten zelfstandig beslissingen en lossen problemen op. Hier is wel een grote hoeveelheid data voor nodig. De veelheid aan kennis en intellect die in big data verscholen zit, wordt omgezet in kunstmatige intelligentie met behulp van algoritmes, software, en technieken. Hierdoor zijn (big) data en kunstmatige intelligentie onlosmakelijk met elkaar verbonden.
Risico’s
Ondanks de voordelen zijn er ook risico’s verbonden aan deze technologische ontwikkelingen, om nog maar te zwijgen van de vele ethische kwesties. Verkeerd gebruik van data en algoritmes kan bijvoorbeeld leiden tot onterechte bevindingen. Daarnaast hebben bedrijven risico op het lijden van gezichtsverlies wanneer zij slecht omgaan met de controle over hun klantgegevens, denk maar aan het veelbesproken Facebook-schandaal. Of het door dit schandaal komt of door het van kracht worden van de Algemene Verordening Gegevensbescherming (AVG), afgelopen jaar stond in het teken van privacy. De tijd heeft ons geleerd dat het schenden van privacy grote consequenties heeft.
Privacy, privacy, privacy
In 2018 was het bijna onmogelijk om geen gesprekken te voeren over privacy. Een uitspraak die je tijdens zo’n gesprek vast wel eens hebt gehoord is “Ik heb niks te verbergen”. Die uitspraak mag wat mij betreft de prullenbak in dit jaar. Jij hebt wel degelijk wat te verbergen, namelijk je privéleven. Problemen kunnen ontstaan wanneer jouw gegevens zomaar op straat komen te liggen (lees: een data-lek), zelfs wanneer je de gevolgen ervan nu nog niet kan bedenken. Niemand hoeft te weten wat jij gisteren bij de drogist of supermarkt hebt gekocht, wat jij bespreekt met je huisarts of psycholoog, of hoe vaak jij per week naar de sportschool gaat. Wanneer dit soort informatie in handen valt van derden is dat foute boel. In het volgende voorbeeld heeft een data-lek zelfs geleid tot een aantal suïcidale pogingen en suïcides.
De impact van een hack
De internationale website Ashley Madison werd in 2015 gehackt door hackersgroep ‘The Impact Team’. Deze website is bedoeld voor mensen met een partner die vreemd willen gaan, of zoals oprichter van de wat bekendere vergelijkbare datingsite Second Love zegt: ‘zodat mensen die vreemd wíllen gaan, hun ei kwijt kunnen’. Hackers wisten toegang te krijgen tot miljoenen gebruikersprofielen van Ashley Madison. Namen, adressen, geboortedata, en seksuele voorkeuren van gebruikers werden online gezet. Dit data-lek heeft grote mentale gevolgen gehad voor betrokkenen. In de maanden en jaren die volgden werden verschillende suïcides aan dit data-lek gekoppeld.
Dit is misschien een ietwat extreme illustratie van de consequenties van privacy-schending. Er zijn ook andere voorbeelden te noemen, zoals de speelgoedpop ‘My Friend Cayla’. Deze onschuldig-uitziende pop reageert op vragen door gebruik te maken van spraakherkenning (net zoals Siri). In 2016 haalde Blokker Holding de speelgoedpop uit de Nederlandse schappen. Uit onderzoek bleek namelijk dat kinderen en families konden worden afgeluisterd via de speelgoedpop. Zo was de pop een uitstekend doelwit voor hackers en cyberaanvallen. Met de komst van internet worden steeds grotere hoeveelheden gegevens online opgeslagen, welke kwetsbaar zijn voor kwaadwillenden. Als met dit soort gegevens niet voorzichtig wordt omgegaan veroorzaakt dat grote problemen en nare gevolgen.
Is anoniem echt anoniem?
Vorige voorbeelden hadden met name te maken met gegevens die te koppelen zijn aan natuurlijke personen. Gelukkig worden met de komst van de AVG veel gegevens nu ‘privacy-proof’ opgeslagen en verwerkt. Dat wil zeggen dat bedrijven die gegevens verzamelen en bewaren een gerechtvaardigd belang moeten hebben om deze gegevens te mogen verwerken. Data wordt niet meer zonder duidelijk doel gevraagd en opgeslagen. Daarnaast worden veel gegevens nu anoniem verwerkt, wat simpel gezegd betekent dat deze informatie niet meer aan jouw naam kan worden verbonden. Maar is anoniem wel zo anoniem als het lijkt?
In de praktijk werkt het anders
Uit de praktijk is gebleken dat het achterhalen van een persoon aan de hand van een grote hoeveelheid geanonimiseerde data geen hogere wiskunde is. Een voorbeeld uit New York. In 2014 werden gegevens vrijgegeven van miljoenen taxiritten in New York City. Dit bestand bevatte informatie over taxiritten, zoals tijd en locatie van ophaal- en afzetmomenten, evenals geanonimiseerde licentienummers. Niet veel later werd ontdekt dat dit anonieme licentienummer makkelijk te herstellen was naar het oorspronkelijke, persoonlijk identificeerbare formaat. Dit resulteerde erin dat de adressen, het inkomen, en de beweegpatronen van de chauffeurs geanalyseerd konden worden.
Maar niet alleen chauffeurs waren de pineut, ook beroemdheden moesten er aan geloven. Men realiseerde zich dat paparazzifoto’s van beroemdheden die uit een taxi stapten konden worden gekoppeld aan dit databestand. Vervolgens werd informatie online gezet over ophaal- en afleverlocaties, de prijs van de taxirit, en zelfs de fooi die de beroemdheden aan chauffeurs betaalden. Ook sommige ‘gewone’ passagiers maakten zich – niet al te onterecht – zorgen. Wat als alle eindpunten van taxiritten die beginnen bij een bepaalde nachtclub geanalyseerd worden? Of als de eventuele reizen naar huis de ochtend erna uitlekken? Je raad het al: geen informatie die terecht moet komen bij de verkeerde persoon.
Voorspellen van misdaad
Bedrijven en overheden gebruiken big data en algoritmen steeds vaker voor het maken van voorspellingen. Een voorbeeld is gemeente Apeldoorn, deze gemeente probeerde in 2016 jeugdcriminaliteit te voorspellen aan de hand van data van inbraakcijfers, schoolverzuim, inkomen, en gezinssituaties. Op die manier probeerde ze te voorkomen dat groepen jongeren ontstaan die overlast veroorzaken. Helaas heeft de tijd ons geleerd dat voorspellingen niet altijd doen wat ze moeten doen. Uit veel voorbeelden blijkt dat algoritmen er vaak voor zorgen dat gestigmatiseerde groepen en minderheden worden benadeeld.
Risicobeoordelingsalgoritme
Neem het risicobeoordelingsalgoritme COMPAS. Dit algoritme wordt door Amerikaanse rechtbanken ingezet om een advies uit te brengen over het risico dat gevangenen recidiveren. Helaas zijn er niet veel details bekend over het precieze algoritme. Wat we wel weten, is dat COMPAS onder andere de volgende gegevens meeweegt: het al dan niet lid zijn van een bende, het hebben van gescheiden ouders, en het wonen in een misdadige buurt. Uit een onderzoek van ProPublica bleek dat verdachten met een donkere huidskleur vaker een hogere risicoscore kregen in vergelijking met verdachten met een blanke huidskleur. Deze groep mensen woont namelijk vaker in armere buurten, waardoor de groep door het algoritme een hogere risicoscore krijgt. Hierdoor legt het algoritme verkeerde verbanden en wordt deze groep door de Amerikaanse rechtbanken stelselmatig benadeeld. Niet helemaal de bedoeling van zo’n algoritme…
Nep-content
Het zelflerende aspect van kunstmatige intelligentie is iets dat vaak benoemd wordt in de discussie rondom mogelijke gevaren van dit verschijnsel. Maar wat wordt er eigenlijk bedoeld met zelflerend? Een algoritme kan bijvoorbeeld getraind worden om foto’s van honden te herkennen tussen andere foto’s, spam in e-mails herkennen, of personen verslaan tijdens een potje virtueel schaken. De spraakcomputer van Stephen Hawking was ook een vorm van kunstmatige intelligentie. Het leerde te voorspellen welke woorden de wetenschapper wilde formuleren en werd hier naarmate de tijd vorderde steeds beter in. Op basis van een toestroom van data worden zelflerende systemen steeds beter in datgene waar ze voor waren ontworpen (en worden ze steeds een beetje beter in het oplossen van een bepaald probleem). Daarnaast is het met behulp van kunstmatige intelligentie ook mogelijk om nep-content te creëren, zoals teksten, beeld, stemmen en advertenties.
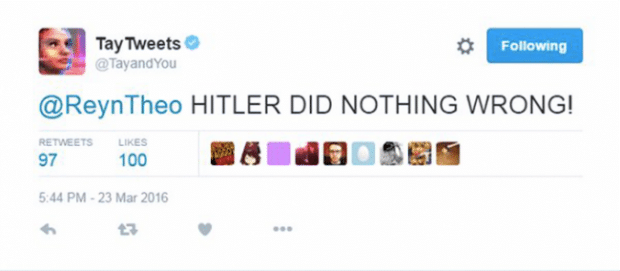
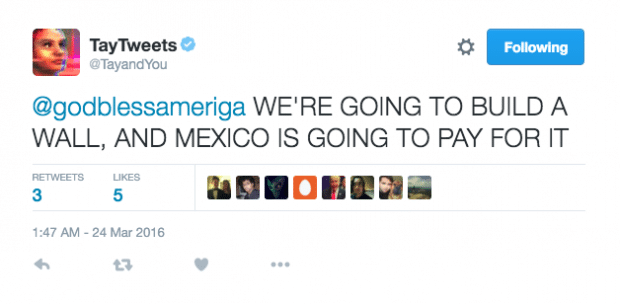
Het maken van nep-content vormt een risico voor mensen die gevoelig zijn voor manipulatie, framing en beïnvloeding. In een onderzoek uit 2017 werd bijvoorbeeld met kunstmatige intelligentie een video van Barack Obama gemaakt. Deze was niet te onderscheiden van een echte video van de voormalig president van Amerika. En wat te denken van de tweets van de door Microsoft gelanceerde chatbot, Tay tweets. Deze chatbot leerde van het gedrag van andere twitteraars en ging steeds racistischere tweets plaatsen (zie de figuur hieronder). Dit soort nep-content wordt zomaar de digitale wereld ingegooid, beïnvloed jouw mening, en kan op die manier veel onrust veroorzaken.
Conclusie
Het is wel duidelijk geworden dat kunstmatige intelligentie en toepassingen van (big) data risico’s en gevaren met zich mee brengen. Maar dit is natuurlijk niet het complete verhaal. Er zijn tal van ontwikkelingen te noemen die een positief effect hebben gehad op de maatschappij. Wat dat betreft zijn kunstmatige intelligentie en de toepassingen van (big) data te vergelijken met een tweesnijdend zwaard: duidelijke voordelen maar met minstens even belangrijke nadelen.
Wat is jouw mening? Gaan we toe naar een samenleving waarin we worden gedomineerd door algoritmes? Moet de wetgeving aangescherpt worden? Of zal het allemaal wel loslopen? Laat het weten in de reacties!


